Want to automatically extract data from websites without copying and pasting for hours? Web scraping with Python lets you do exactly that.
Python remains the go-to language for scraping because of its readable syntax and massive library ecosystem. Whether you're collecting product prices, monitoring competitor websites, or building datasets for machine learning, this guide has you covered.
In this guide, you'll learn how to build scrapers that work on both static HTML pages and JavaScript-heavy dynamic sites. We'll cover multiple approaches from simple HTTP requests to full browser automation.
What Is Web Scraping with Python?
Web scraping with Python involves writing automated scripts that fetch web pages, parse their HTML content, and extract specific data elements. The process mimics what a human does when browsing—visiting URLs, reading content, and copying information—but at machine speed.
Python dominates the scraping landscape because it offers libraries for every step of the process. You can send HTTP requests with requests, parse HTML with BeautifulSoup, control browsers with Playwright or Selenium, and build full crawlers with Scrapy.
The scraping workflow breaks down into four stages. First, you connect to the target page. Second, you retrieve its HTML content. Third, you locate and extract the data you need. Fourth, you store that data in a usable format like CSV or JSON.
Static sites return complete HTML from the server. Dynamic sites load content through JavaScript after the initial page load. These two types require different scraping approaches.
Setting Up Your Python Scraping Environment
Before writing any scraping code, you need a properly configured Python environment. This prevents library conflicts and keeps your projects organized.
Prerequisites
You need Python 3.8 or newer installed on your system. Check your version by running this command in your terminal:
python3 --version
You should see output like Python 3.11.4 or similar. If Python isn't installed, download it from the official Python website.
Creating a Virtual Environment
Virtual environments isolate your project dependencies. Create one with these commands:
mkdir python-scraper
cd python-scraper
python3 -m venv venv
Activate the virtual environment. On macOS and Linux:
source venv/bin/activate
On Windows:
venv\Scripts\activate
Your terminal prompt should now show (venv) indicating the environment is active. All packages you install will stay within this environment.
Installing Core Libraries
Install the essential scraping libraries with pip:
pip install requests beautifulsoup4 lxml playwright selenium scrapy
This installs everything you need for both static and dynamic scraping. We'll cover each library in detail throughout this guide.
Method 1: Scraping Static Sites with Requests and Beautiful Soup
For static HTML pages, the combination of requests and BeautifulSoup provides the fastest and simplest approach. This method works when the data you want exists in the initial HTML response from the server.
Understanding Static vs Dynamic Content
Open your browser's developer tools and view the page source. If you can see the data you want in that raw HTML, the page is static.
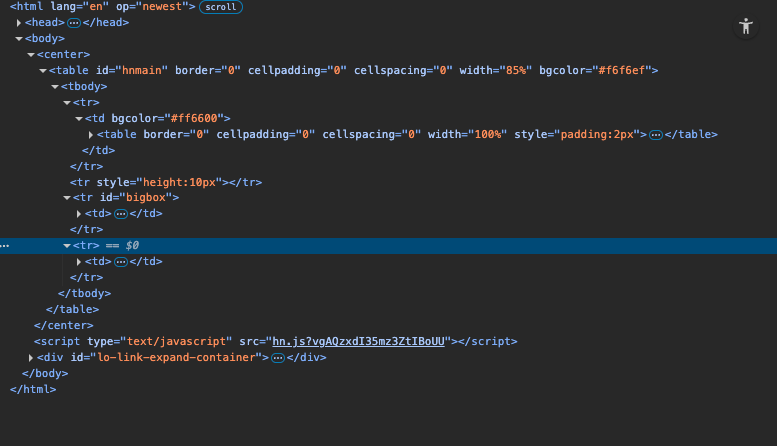
If the source shows empty containers or JavaScript variables, the page loads content dynamically.
Making HTTP Requests
The requests library handles HTTP communication. Here's how to fetch a webpage:
import requests
url = "https://quotes.toscrape.com/"
response = requests.get(url)
print(response.status_code) # Should be 200
print(response.text[:500]) # First 500 characters of HTML
The get() method sends an HTTP GET request to the specified URL. The response object contains the status code, headers, and the page content in the text attribute.
Always check the status code before parsing. A 200 means success. Codes like 403 or 429 indicate blocking or rate limiting.
Adding Request Headers
Websites can detect scrapers by examining request headers. Mimic a real browser by setting appropriate headers:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
}
url = "https://quotes.toscrape.com/"
response = requests.get(url, headers=headers)
The User-Agent header tells the server which browser you're using. Using a current Chrome or Firefox user agent reduces the chance of being blocked.
Parsing HTML with Beautiful Soup
Beautiful Soup transforms raw HTML text into a navigable tree structure. You can then search for elements using tag names, CSS classes, or CSS selectors.
from bs4 import BeautifulSoup
html = response.text
soup = BeautifulSoup(html, "lxml")
# Find elements by tag
all_divs = soup.find_all("div")
# Find by class
quotes = soup.find_all("div", class_="quote")
# Find by CSS selector
authors = soup.select(".author")
The lxml parser offers better performance than Python's built-in html.parser. Install it with pip install lxml if you haven't already.
Extracting Data from Elements
Once you've located elements, extract their text content or attribute values:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
# Get text content
quote_element = soup.select_one(".text")
quote_text = quote_element.get_text(strip=True)
# Get attribute value
link_element = soup.select_one("a")
href = link_element.get("href")
# Get all text from nested elements
full_text = soup.get_text(separator=" ", strip=True)
The get_text() method extracts visible text from an element and its children.
The strip=True parameter removes leading and trailing whitespace.
Complete Static Scraping Example
Here's a full working scraper that extracts quotes from the practice site:
import requests
from bs4 import BeautifulSoup
import csv
def scrape_quotes():
"""Scrape all quotes from quotes.toscrape.com"""
base_url = "https://quotes.toscrape.com"
all_quotes = []
page = 1
while True:
# Build URL for current page
url = f"{base_url}/page/{page}/"
# Fetch the page
response = requests.get(url)
# Check if page exists
if response.status_code != 200:
break
# Parse HTML
soup = BeautifulSoup(response.text, "lxml")
# Find all quote containers
quote_elements = soup.select(".quote")
# Stop if no quotes found
if not quote_elements:
break
# Extract data from each quote
for quote in quote_elements:
text = quote.select_one(".text").get_text(strip=True)
author = quote.select_one(".author").get_text(strip=True)
tags = [tag.get_text() for tag in quote.select(".tag")]
all_quotes.append({
"text": text,
"author": author,
"tags": ", ".join(tags)
})
print(f"Scraped page {page}: {len(quote_elements)} quotes")
page += 1
return all_quotes
# Run the scraper
quotes = scrape_quotes()
print(f"Total quotes collected: {len(quotes)}")
This scraper automatically handles pagination by incrementing the page number until no more quotes appear. The while loop continues until either the server returns an error or no quote elements exist on the page.
Method 2: Scraping Dynamic Sites with Playwright
Modern websites often load content through JavaScript after the initial page render. Traditional HTTP clients can't execute JavaScript, so you need a browser automation tool.
Playwright, developed by Microsoft, provides fast and reliable browser automation. It supports Chromium, Firefox, and WebKit, offering cross-browser compatibility.
Installing Playwright
Install Playwright and download the browser binaries:
pip install playwright
playwright install
The second command downloads Chromium, Firefox, and WebKit browsers that Playwright will control.
Basic Playwright Usage
Playwright launches a real browser and lets you interact with pages programmatically:
from playwright.sync_api import sync_playwright
def scrape_dynamic_page():
with sync_playwright() as p:
# Launch browser in headless mode
browser = p.chromium.launch(headless=True)
# Create new page
page = browser.new_page()
# Navigate to URL
page.goto("https://quotes.toscrape.com/scroll")
# Wait for content to load
page.wait_for_selector(".quote")
# Get page content
content = page.content()
print(content[:1000])
# Close browser
browser.close()
scrape_dynamic_page()
The headless=True parameter runs the browser without a visible window. Set it to False during development to watch your scraper work.
Waiting for Dynamic Content
Dynamic pages require explicit waits. The content might not exist immediately after navigation completes.
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://quotes.toscrape.com/scroll")
# Wait for specific element
page.wait_for_selector(".quote", timeout=10000)
# Or wait for network to be idle
page.wait_for_load_state("networkidle")
# Extract data
quotes = page.locator(".quote").all()
for quote in quotes:
text = quote.locator(".text").text_content()
author = quote.locator(".author").text_content()
print(f"{author}: {text[:50]}...")
browser.close()
The timeout parameter specifies how long to wait in milliseconds. Increase it for slow-loading pages.
Handling Infinite Scroll
Some sites load more content as you scroll down. Automate scrolling to trigger these loads:
from playwright.sync_api import sync_playwright
import time
def scrape_infinite_scroll():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://quotes.toscrape.com/scroll")
# Scroll to load all content
previous_height = 0
while True:
# Scroll to bottom
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Wait for new content
time.sleep(2)
# Get new height
new_height = page.evaluate("document.body.scrollHeight")
# Break if no new content loaded
if new_height == previous_height:
break
previous_height = new_height
# Now extract all loaded quotes
quotes = page.locator(".quote").all()
print(f"Found {len(quotes)} quotes after scrolling")
browser.close()
scrape_infinite_scroll()
This script scrolls until the page height stops increasing, indicating all content has loaded.
Complete Playwright Scraping Example
Here's a production-ready scraper for dynamic content:
from playwright.sync_api import sync_playwright
import json
import time
def scrape_dynamic_quotes():
"""Scrape quotes from dynamic JavaScript-rendered page"""
all_quotes = []
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
# Set viewport size
page = browser.new_page(viewport={"width": 1920, "height": 1080})
# Navigate to page
page.goto("https://quotes.toscrape.com/scroll")
# Wait for initial quotes
page.wait_for_selector(".quote")
# Scroll to load all quotes
for _ in range(10): # Maximum 10 scroll attempts
page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(1)
# Extract quotes using Playwright locators
quote_elements = page.locator(".quote").all()
for element in quote_elements:
text = element.locator(".text").text_content()
author = element.locator(".author").text_content()
# Clean the text
text = text.strip().strip('"').strip('"')
author = author.strip()
all_quotes.append({
"text": text,
"author": author
})
browser.close()
return all_quotes
# Run scraper
quotes = scrape_dynamic_quotes()
# Save to JSON
with open("quotes.json", "w", encoding="utf-8") as f:
json.dump(quotes, f, indent=2, ensure_ascii=False)
print(f"Saved {len(quotes)} quotes to quotes.json")
Method 3: Browser Automation with Selenium
Selenium has been the industry standard for browser automation for over a decade. While Playwright is newer and often faster, Selenium remains widely used and well-documented.
Installing Selenium
Install Selenium with pip:
pip install selenium
Modern Selenium (version 4.6+) automatically downloads the correct browser driver. You just need Chrome or Firefox installed on your system.
Basic Selenium Usage
Selenium controls browsers through a WebDriver interface:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
def basic_selenium_scrape():
# Configure Chrome options
options = Options()
options.add_argument("--headless") # Run without GUI
# Initialize driver
driver = webdriver.Chrome(options=options)
try:
# Navigate to page
driver.get("https://quotes.toscrape.com/")
# Find elements
quotes = driver.find_elements(By.CSS_SELECTOR, ".quote")
for quote in quotes:
text = quote.find_element(By.CSS_SELECTOR, ".text").text
author = quote.find_element(By.CSS_SELECTOR, ".author").text
print(f"{author}: {text[:50]}...")
finally:
# Always close the driver
driver.quit()
basic_selenium_scrape()
The try/finally block ensures the browser closes even if an error occurs. Failing to close browsers leads to resource leaks.
Explicit Waits in Selenium
Selenium's explicit waits handle dynamic content loading:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def selenium_with_waits():
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
try:
driver.get("https://quotes.toscrape.com/scroll")
# Wait up to 10 seconds for quotes to appear
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, ".quote")))
quotes = driver.find_elements(By.CSS_SELECTOR, ".quote")
print(f"Found {len(quotes)} quotes")
finally:
driver.quit()
selenium_with_waits()
Expected conditions include presence_of_element_located, visibility_of_element_located, element_to_be_clickable, and many more.
Interacting with Page Elements
Selenium can fill forms, click buttons, and simulate keyboard input:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
def selenium_interactions():
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
try:
driver.get("https://quotes.toscrape.com/login")
# Find and fill username field
username = driver.find_element(By.ID, "username")
username.send_keys("testuser")
# Find and fill password field
password = driver.find_element(By.ID, "password")
password.send_keys("testpass")
# Submit the form
password.send_keys(Keys.RETURN)
# Wait for redirect
import time
time.sleep(2)
print(f"Current URL: {driver.current_url}")
finally:
driver.quit()
selenium_interactions()
Method 4: Using Scrapy for Large-Scale Scraping
Scrapy is a complete web crawling framework designed for extracting data from websites at scale. Unlike simple scripts, Scrapy handles concurrency, rate limiting, and data pipelines automatically.
Installing Scrapy
Install Scrapy with pip:
pip install scrapy
Creating a Scrapy Project
Scrapy uses a project structure. Create one with the command line tool:
scrapy startproject quotescraper
cd quotescraper
scrapy genspider quotes quotes.toscrape.com
This creates a directory structure with configuration files and a spider template.
Writing a Scrapy Spider
Spiders define how to crawl pages and extract data. Edit the generated spider file:
# quotescraper/spiders/quotes.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = ["https://quotes.toscrape.com/"]
def parse(self, response):
# Extract quotes from current page
for quote in response.css(".quote"):
yield {
"text": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"tags": quote.css(".tag::text").getall()
}
# Follow pagination links
next_page = response.css("li.next a::attr(href)").get()
if next_page:
yield response.follow(next_page, self.parse)
The yield statement returns extracted data and continues crawling. Scrapy handles the asynchronous execution behind the scenes.
Running the Spider
Run your spider from the command line:
scrapy crawl quotes -o quotes.json
The -o flag specifies the output file. Scrapy supports JSON, CSV, and XML formats natively.
Configuring Scrapy Settings
Adjust settings in settings.py to control crawling behavior:
# quotescraper/settings.py
# Respect robots.txt
ROBOTSTXT_OBEY = True
# Add delay between requests
DOWNLOAD_DELAY = 1
# Limit concurrent requests
CONCURRENT_REQUESTS = 8
# Set user agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0"
# Enable auto-throttle
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 1
AUTOTHROTTLE_MAX_DELAY = 10
The auto-throttle feature automatically adjusts request rates based on server response times. This helps avoid overloading target servers.
Handling Anti-Bot Protection
Websites increasingly deploy anti-bot measures to block scrapers. Understanding these defenses helps you build more resilient scrapers.
Common Anti-Bot Techniques
Rate limiting restricts how many requests an IP address can make within a time period. Exceed the limit and you'll receive 429 errors or temporary blocks.
JavaScript challenges require browsers to execute scripts before accessing content. Simple HTTP clients fail these checks immediately.
CAPTCHAs ask users to solve puzzles proving they're human. These appear after suspicious activity detection.
Fingerprinting analyzes browser characteristics like screen resolution, installed fonts, and WebGL capabilities. Headless browsers often have detectable fingerprints.
Rotating User Agents
Vary your User-Agent header to appear as different browsers:
import random
import requests
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Safari/605.1.15",
]
def get_random_headers():
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=get_random_headers())
Adding Request Delays
Avoid triggering rate limits by spacing out requests:
import time
import random
def respectful_scrape(urls):
results = []
for url in urls:
response = requests.get(url, headers=get_random_headers())
results.append(response.text)
# Random delay between 1 and 3 seconds
delay = random.uniform(1, 3)
time.sleep(delay)
return results
Random delays appear more natural than fixed intervals.
Handling Request Failures
Build retry logic for transient failures:
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
def create_session_with_retries():
session = requests.Session()
retries = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retries)
session.mount("http://", adapter)
session.mount("https://", adapter)
return session
session = create_session_with_retries()
response = session.get(url)
The backoff factor increases wait time between retries exponentially.
Using Proxies for Web Scraping
Proxies route your requests through different IP addresses. This helps avoid IP-based blocks and rate limits.
Types of Proxies
Datacenter proxies come from cloud servers. They're fast and cheap but easily detected.
Residential proxies use IP addresses from real ISP customers. They appear legitimate but cost more.
Mobile proxies route through cellular networks. They're hardest to detect but most expensive.
Rotating proxies automatically switch IPs for each request. This provides the best protection against blocks.
If you need reliable proxies for your scraping projects, providers like Roundproxies.com offer residential, datacenter, ISP, and mobile proxy options with automatic rotation.
Implementing Proxy Rotation
Here's how to rotate proxies with requests:
import requests
import random
PROXIES = [
"http://user:pass@proxy1.example.com:8080",
"http://user:pass@proxy2.example.com:8080",
"http://user:pass@proxy3.example.com:8080",
]
def get_with_proxy(url):
proxy = random.choice(PROXIES)
proxies = {
"http": proxy,
"https": proxy
}
response = requests.get(url, proxies=proxies, timeout=30)
return response
response = get_with_proxy("https://example.com")
Using Proxies with Playwright
Playwright supports proxy configuration at browser launch:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(
headless=True,
proxy={
"server": "http://proxy.example.com:8080",
"username": "user",
"password": "pass"
}
)
page = browser.new_page()
page.goto("https://example.com")
browser.close()
Using Proxies with Selenium
Configure Selenium to use proxies through Chrome options:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def selenium_with_proxy(proxy_url):
options = Options()
options.add_argument("--headless")
options.add_argument(f"--proxy-server={proxy_url}")
driver = webdriver.Chrome(options=options)
return driver
driver = selenium_with_proxy("http://proxy.example.com:8080")
driver.get("https://example.com")
driver.quit()
Storing Scraped Data
Once you've extracted data, you need to store it in a useful format. The choice depends on data structure and intended use.
Saving to CSV
CSV works well for tabular data with consistent fields:
import csv
def save_to_csv(data, filename):
if not data:
return
fieldnames = data[0].keys()
with open(filename, "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(data)
quotes = [
{"text": "Quote 1", "author": "Author 1"},
{"text": "Quote 2", "author": "Author 2"}
]
save_to_csv(quotes, "quotes.csv")
Saving to JSON
JSON preserves nested structures and mixed data types:
import json
def save_to_json(data, filename):
with open(filename, "w", encoding="utf-8") as f:
json.dump(data, f, indent=2, ensure_ascii=False)
quotes = [
{"text": "Quote 1", "author": "Author 1", "tags": ["wisdom", "life"]},
{"text": "Quote 2", "author": "Author 2", "tags": ["humor"]}
]
save_to_json(quotes, "quotes.json")
Saving to SQLite Database
Databases handle large datasets and enable complex queries:
import sqlite3
def save_to_sqlite(data, db_name, table_name):
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
# Create table
cursor.execute(f"""
CREATE TABLE IF NOT EXISTS {table_name} (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT,
author TEXT,
tags TEXT
)
""")
# Insert data
for item in data:
cursor.execute(
f"INSERT INTO {table_name} (text, author, tags) VALUES (?, ?, ?)",
(item["text"], item["author"], ", ".join(item.get("tags", [])))
)
conn.commit()
conn.close()
save_to_sqlite(quotes, "quotes.db", "quotes")
Common Mistakes and How to Avoid Them
Years of web scraping with Python experience reveal patterns in what goes wrong. Learning from these mistakes saves hours of debugging.
Not Handling Errors Gracefully
Network requests fail. Servers go down. Elements disappear. Wrap critical code in try/except blocks:
import requests
from bs4 import BeautifulSoup
def safe_scrape(url):
try:
response = requests.get(url, timeout=30)
response.raise_for_status()
soup = BeautifulSoup(response.text, "lxml")
title = soup.select_one("h1")
return title.get_text() if title else None
except requests.RequestException as e:
print(f"Request failed: {e}")
return None
except Exception as e:
print(f"Parsing failed: {e}")
return None
Ignoring robots.txt
The robots.txt file specifies which pages scrapers should avoid. Respecting it demonstrates good citizenship:
from urllib.robotparser import RobotFileParser
def can_scrape(url, user_agent="*"):
parser = RobotFileParser()
# Find robots.txt URL
from urllib.parse import urlparse
parsed = urlparse(url)
robots_url = f"{parsed.scheme}://{parsed.netloc}/robots.txt"
parser.set_url(robots_url)
parser.read()
return parser.can_fetch(user_agent, url)
if can_scrape("https://example.com/page"):
# Proceed with scraping
pass
Scraping Too Aggressively
Hammering servers with requests can get you blocked and may even cause legal issues. Always add delays and respect rate limits.
Not Validating Extracted Data
Empty or malformed data causes downstream problems. Validate before saving:
def validate_quote(quote):
if not quote.get("text"):
return False
if not quote.get("author"):
return False
if len(quote["text"]) < 10:
return False
return True
valid_quotes = [q for q in quotes if validate_quote(q)]
Hardcoding Selectors
Websites change their HTML structure frequently. Make selectors configurable:
SELECTORS = {
"quote_container": ".quote",
"quote_text": ".text",
"quote_author": ".author",
"next_page": "li.next a"
}
def scrape_with_config(soup, selectors):
quotes = []
for container in soup.select(selectors["quote_container"]):
text_el = container.select_one(selectors["quote_text"])
author_el = container.select_one(selectors["quote_author"])
if text_el and author_el:
quotes.append({
"text": text_el.get_text(strip=True),
"author": author_el.get_text(strip=True)
})
return quotes
Advanced Techniques for 2026
The scraping landscape continues to evolve. Here are cutting-edge approaches that will define web scraping with Python in 2026 and beyond.
Async Scraping with HTTPX
HTTPX offers async capabilities that dramatically speed up scraping multiple pages:
import httpx
import asyncio
from bs4 import BeautifulSoup
async def fetch_page(client, url):
"""Fetch a single page asynchronously"""
response = await client.get(url)
return response.text
async def scrape_multiple_pages(urls):
"""Scrape multiple pages concurrently"""
async with httpx.AsyncClient() as client:
# Create tasks for all URLs
tasks = [fetch_page(client, url) for url in urls]
# Execute all requests concurrently
pages = await asyncio.gather(*tasks)
results = []
for html in pages:
soup = BeautifulSoup(html, "lxml")
# Extract data from each page
title = soup.select_one("h1")
if title:
results.append(title.get_text(strip=True))
return results
# Generate URLs for first 10 pages
urls = [f"https://quotes.toscrape.com/page/{i}/" for i in range(1, 11)]
# Run async scraper
results = asyncio.run(scrape_multiple_pages(urls))
print(f"Scraped {len(results)} pages")
Async scraping can be 5-10x faster than synchronous approaches when scraping many pages.
AI-Powered Data Extraction
Large language models can extract structured data from messy HTML without brittle CSS selectors:
import openai
from bs4 import BeautifulSoup
def extract_with_ai(html, prompt):
"""Use AI to extract structured data from HTML"""
# Clean HTML to reduce tokens
soup = BeautifulSoup(html, "lxml")
text = soup.get_text(separator="\n", strip=True)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Extract structured data from the provided text."},
{"role": "user", "content": f"{prompt}\n\nText:\n{text[:4000]}"}
]
)
return response.choices[0].message.content
# Example usage
prompt = "Extract all product names and prices as JSON"
result = extract_with_ai(html, prompt)
This approach handles layout changes gracefully since it focuses on semantic meaning rather than DOM structure.
Headless Browser Stealth Mode
Modern anti-bot systems detect headless browsers through various fingerprinting techniques. Use stealth plugins to appear more human:
from playwright.sync_api import sync_playwright
from playwright_stealth import stealth_sync
def stealth_scrape(url):
"""Scrape with stealth mode to avoid detection"""
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Apply stealth settings
stealth_sync(page)
# Now navigate
page.goto(url)
content = page.content()
browser.close()
return content
Install the stealth plugin with pip install playwright-stealth.
Building Resilient Scrapers
Production scrapers need monitoring and automatic recovery:
import logging
import time
from datetime import datetime
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('scraper.log'),
logging.StreamHandler()
]
)
class ResilientScraper:
def __init__(self, max_retries=3, backoff_factor=2):
self.max_retries = max_retries
self.backoff_factor = backoff_factor
self.stats = {
"success": 0,
"failed": 0,
"retries": 0
}
def scrape_with_retry(self, url, scrape_func):
"""Attempt scraping with exponential backoff"""
for attempt in range(self.max_retries):
try:
result = scrape_func(url)
self.stats["success"] += 1
logging.info(f"Successfully scraped: {url}")
return result
except Exception as e:
self.stats["retries"] += 1
wait_time = self.backoff_factor ** attempt
logging.warning(
f"Attempt {attempt + 1} failed for {url}: {e}. "
f"Retrying in {wait_time}s"
)
time.sleep(wait_time)
self.stats["failed"] += 1
logging.error(f"All attempts failed for: {url}")
return None
def get_stats(self):
return self.stats
Distributed Scraping Architecture
For very large projects, distribute scraping across multiple machines:
# Simple task queue using Redis
import redis
import json
class ScrapingQueue:
def __init__(self, redis_url="redis://localhost:6379"):
self.redis = redis.from_url(redis_url)
self.queue_name = "scraping_tasks"
self.results_name = "scraping_results"
def add_task(self, url):
"""Add URL to scraping queue"""
task = {"url": url, "added_at": datetime.now().isoformat()}
self.redis.lpush(self.queue_name, json.dumps(task))
def get_task(self):
"""Get next URL from queue"""
task_json = self.redis.rpop(self.queue_name)
if task_json:
return json.loads(task_json)
return None
def save_result(self, url, data):
"""Save scraping result"""
result = {"url": url, "data": data}
self.redis.lpush(self.results_name, json.dumps(result))
def pending_count(self):
"""Get count of pending tasks"""
return self.redis.llen(self.queue_name)
Run multiple worker processes that pull URLs from the shared queue. This scales horizontally across machines.
Comparing Python Scraping Libraries
Here's a quick comparison to help you choose the right tool:
| Library | Best For | Learning Curve | Speed | Dynamic Content |
|---|---|---|---|---|
| Requests + BS4 | Static sites | Easy | Fast | No |
| HTTPX | Async static scraping | Medium | Very Fast | No |
| Playwright | Dynamic sites, stealth | Medium | Medium | Yes |
| Selenium | Legacy projects, testing | Medium | Slow | Yes |
| Scrapy | Large-scale crawling | Hard | Fast | With plugins |
Choose based on your specific requirements. Start simple and add complexity only when needed.
Ethical Scraping Best Practices
Responsible scraping benefits everyone. Follow these guidelines to maintain good relationships with target sites.
Respecting Server Resources
Your scraper impacts real infrastructure. Space out requests to avoid overwhelming servers:
import time
import random
def polite_scraper(urls, min_delay=1, max_delay=3):
"""Scrape with respectful delays"""
for url in urls:
# Your scraping logic here
yield scrape_page(url)
# Random delay appears more natural
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)
Checking Terms of Service
Many websites explicitly address scraping in their terms. Review these before starting any project. Some sites offer official APIs that provide cleaner data access.
Identifying Your Scraper
Include contact information in your User-Agent so site owners can reach you:
USER_AGENT = "MyScraperBot/1.0 (+https://mysite.com/scraper-info; contact@mysite.com)"
This transparency builds trust and often prevents blocks.
Caching Responses
Don't re-scrape data you already have. Cache responses to reduce server load:
import hashlib
import os
import json
class ResponseCache:
def __init__(self, cache_dir="cache"):
self.cache_dir = cache_dir
os.makedirs(cache_dir, exist_ok=True)
def _get_cache_path(self, url):
"""Generate cache file path from URL"""
url_hash = hashlib.md5(url.encode()).hexdigest()
return os.path.join(self.cache_dir, f"{url_hash}.json")
def get(self, url):
"""Retrieve cached response"""
path = self._get_cache_path(url)
if os.path.exists(path):
with open(path, "r") as f:
return json.load(f)
return None
def set(self, url, data):
"""Cache response data"""
path = self._get_cache_path(url)
with open(path, "w") as f:
json.dump(data, f)
cache = ResponseCache()
# Check cache before requesting
cached = cache.get(url)
if cached:
data = cached
else:
data = scrape_page(url)
cache.set(url, data)
FAQ
Is web scraping with Python legal?
Web scraping with Python exists in a legal gray area. Scraping publicly available data is generally acceptable, but violating a site's terms of service or scraping private information can create legal issues. Always check the target site's terms before scraping.
What's the best Python library for web scraping?
The best tool for web scraping with Python depends on your needs. For static HTML pages, requests plus BeautifulSoup offers the simplest solution. For JavaScript-heavy sites, Playwright provides modern browser automation. Scrapy excels at large-scale crawling projects.
How do I avoid getting blocked while scraping?
Use realistic request headers, add random delays between requests, rotate IP addresses with proxies, and respect the site's robots.txt file. Avoid patterns that distinguish bots from humans.
Can I scrape websites that require login?
Yes. Browser automation tools like Playwright and Selenium can fill login forms and maintain session cookies. For API-based authentication, requests can handle cookies and tokens directly.
How often should I run my scraper?
That depends on how frequently the target data changes. For real-time prices, you might scrape hourly. For static content, weekly or monthly might suffice. Always consider server impact when scheduling frequent scrapes.
What's the difference between web scraping and web crawling?
Scraping extracts specific data from pages you've identified. Crawling discovers pages by following links across a website. Many projects combine both—crawling to find pages, then scraping to extract data.
Conclusion
Web scraping with Python remains one of the most powerful ways to collect data from the internet in 2026. Whether you're building a price monitoring tool, gathering research data, or feeding machine learning models, Python's ecosystem has you covered.
For static sites, start with requests and BeautifulSoup. They're simple, fast, and handle most use cases. When you encounter JavaScript-rendered content, switch to Playwright or Selenium for full browser automation.
Large-scale projects benefit from Scrapy's built-in handling of concurrency, retries, and data pipelines. Its learning curve pays off quickly when you're crawling thousands of pages.
Remember to scrape responsibly. Respect robots.txt files, add delays between requests, and use proxies when needed. Aggressive scraping damages websites and gets your IP banned.
The techniques in this guide form a solid foundation. Practice on the Quotes to Scrape sandbox site until the concepts become second nature. Then apply what you've learned to real-world projects.








