eBay sits on over a billion product listings, making it a goldmine for price monitoring, competitive analysis, and market research. But here's the thing: eBay doesn't want you scraping their site. Their robots.txt file opens with "The use of robots or other automated means to access the eBay site without the express permission of eBay is strictly prohibited."
Yet people scrape eBay every day for legitimate business purposes—tracking competitor prices, monitoring inventory, and analyzing market trends. In this guide, I'll show you how to extract eBay data responsibly, covering everything from basic product scraping to advanced techniques like extracting hidden variant data from JavaScript objects.
What You Can (and Should) Scrape from eBay
Before diving into code, let's talk about what's actually worth scraping and what's ethically defensible:
Fair game:
- Product titles, prices, and descriptions from public listings
- Search results and category data
- Seller ratings and review counts
- Historical pricing trends (if you're storing it yourself)
Off limits:
- Data behind login walls
- Private seller information beyond what's publicly displayed
- Automated purchasing or bidding
- Personal data protected by GDPR
The distinction matters. Courts have generally sided with scrapers collecting publicly available data (see hiQ Labs v. LinkedIn), but eBay's Terms of Service are stricter than most sites. My advice: scrape for research and internal use, not to clone their entire marketplace.
Understanding eBay's Anti-Scraping Measures
eBay employs several layers of protection:
- Rate limiting: Too many requests from one IP triggers temporary blocks
- JavaScript rendering: Critical data loads after the initial HTML response
- Dynamic selectors: HTML structure changes frequently to break scrapers
- Bot detection: Checks for suspicious headers, patterns, and fingerprints
- CAPTCHA challenges: Appears when behavior looks automated
The good news? Most of these can be handled with smart implementation. The bad news? You'll need to respect rate limits or face IP bans.
Method 1: Scraping eBay Product Pages with Python
Let's start with a basic product scraper. We'll use requests and BeautifulSoup to extract product details from a single listing.
Setting Up Your Environment
pip install requests beautifulsoup4 lxml
Basic Product Scraper
Here's a scraper that extracts the essentials from an eBay product page:
import requests
from bs4 import BeautifulSoup
import time
def scrape_ebay_product(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive',
}
response = requests.get(url, headers=headers)
time.sleep(2) # Respectful delay
if response.status_code != 200:
return {"error": f"Failed to fetch page: {response.status_code}"}
soup = BeautifulSoup(response.content, 'lxml')
# Extract product data
product_data = {}
# Product title
title_elem = soup.select_one('h1.x-item-title__mainTitle')
product_data['title'] = title_elem.text.strip() if title_elem else None
Why this works: We're mimicking a real browser with proper headers. The User-Agent string tells eBay we're Chrome on Windows, not a Python script. The 2-second delay between requests keeps us under the radar.
What can go wrong: If you run this script too aggressively, eBay will start returning 403 errors. That's their polite way of saying "slow down."
Extracting Price and Condition
# Price - eBay uses different selectors for auction vs fixed price
price_elem = soup.select_one('.x-price-primary span')
if not price_elem:
price_elem = soup.select_one('[itemprop="price"]')
product_data['price'] = price_elem.get('content') or price_elem.text.strip() if price_elem else None
# Condition
condition_elem = soup.select_one('.x-item-condition-text span')
product_data['condition'] = condition_elem.text.strip() if condition_elem else None
# Seller info
seller_elem = soup.select_one('.ux-seller-section__item--seller a')
product_data['seller'] = seller_elem.text.strip() if seller_elem else None
return product_data
This handles both auction and "Buy It Now" listings by trying multiple selectors.
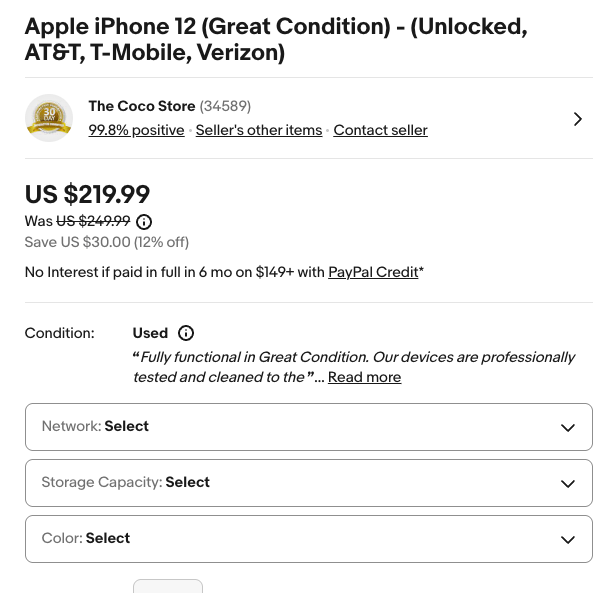
eBay's HTML structure varies depending on the listing type, so defensive coding is essential here.
Handling Images
# Main image
img_elem = soup.select_one('[data-testid="ux-image-carousel-item"] img')
product_data['image_url'] = img_elem.get('src') if img_elem else None
# All images
all_images = soup.select('[data-testid="ux-image-carousel-item"] img')
product_data['all_images'] = [img.get('src') for img in all_images]
The MSKU Object: eBay's Hidden Treasure
Here's where it gets interesting. When you visit an eBay product page with variations (like different sizes or colors), you'll see dropdown menus. But if you inspect the HTML, the prices and stock data for those variations aren't there.
Instead, eBay stores all variant data in a JavaScript object called MSKU (multi-SKU), buried inside a <script> tag. This is one of those techniques that separates working scrapers from broken ones.
Why MSKU Matters
Most scrapers stop at the visible HTML and miss product variants entirely. But MSKU contains:
- All possible variation combinations
- Individual prices for each variant
- Stock status for every option
- Variation IDs that map to dropdown selections
Extracting MSKU Data
import json
import re
def extract_msku_data(html_content):
"""Extract the MSKU object from eBay's JavaScript"""
# Find the MSKU object using regex
pattern = r'"MSKU":\s*(\{.+?\}),"QUANTITY"'
match = re.search(pattern, html_content, re.DOTALL)
if not match:
return None
try:
msku_json = match.group(1)
msku_data = json.loads(msku_json)
return msku_data
except json.JSONDecodeError:
return None
def parse_variants(msku_data):
"""Convert MSKU structure into usable variant data"""
if not msku_data:
return []
variations = msku_data.get('variationsMap', {})
menu_items = msku_data.get('menuItemMap', {})
variation_combos = msku_data.get('variationCombinations', {})
select_menus = msku_data.get('selectMenus', [])
results = []
for combo_key, combo_id in variation_combos.items():
variant_data = variations.get(str(combo_id))
if not variant_data:
continue
variant = {}
# Map dropdown IDs to their display names
menu_ids = [int(i) for i in combo_key.split('_')]
for menu_id in menu_ids:
menu_item = menu_items.get(str(menu_id))
if menu_item:
for menu in select_menus:
if menu_item['valueId'] in menu['menuItemValueIds']:
variant[menu['displayLabel']] = menu_item['displayName']
break
# Extract price
price_data = variant_data.get('binModel', {}).get('price', {})
price_spans = price_data.get('textSpans', [])
variant['price'] = price_spans[0].get('text') if price_spans else None
# Stock status
variant['in_stock'] = not variant_data.get('quantity', {}).get('outOfStock', False)
results.append(variant)
return results
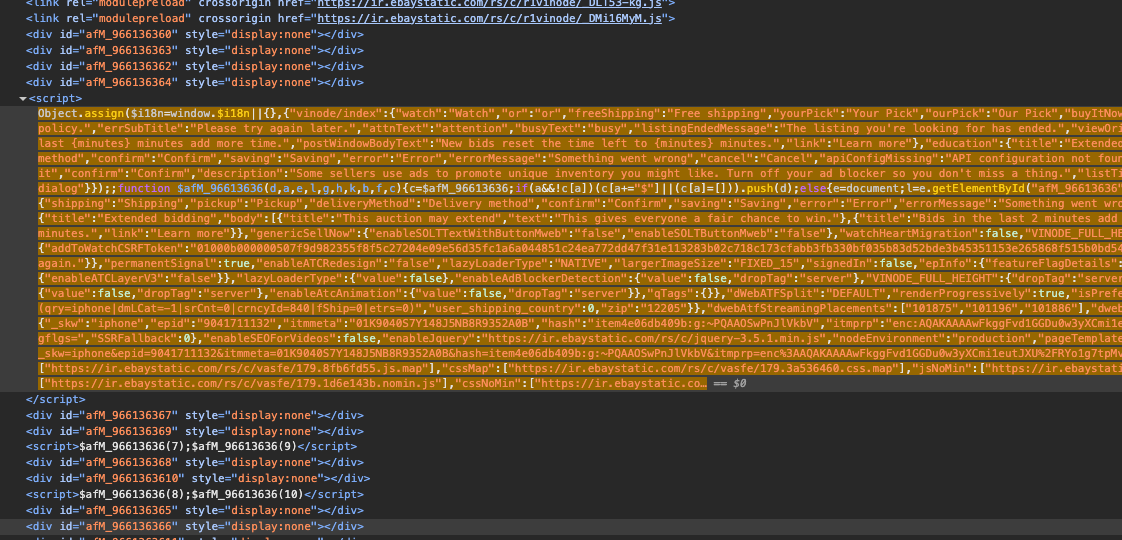
What's happening here:
- The regex pattern finds the MSKU object between
"MSKU":and,"QUANTITY"in the page source - We parse it as JSON (it's valid JSON despite being in JavaScript)
- For each combination, we lookup the display names from
menuItemMapand prices fromvariationsMap
We iterate through variationCombinations
which maps combo IDs to variant data
Why non-greedy matching (.+?): If we used greedy matching (.+), it would capture everything up to the last "QUANTITY" in the entire page, giving us malformed JSON. Non-greedy stops at the first match.
The latest Ebay Scraper Code 2026: https://github.com/carlsfert/web-scraper/tree/main/websites/ebay-scraper
Using MSKU in Practice
def scrape_ebay_product_with_variants(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'lxml')
# Get basic product info
title = soup.select_one('h1.x-item-title__mainTitle')
# Extract MSKU data
msku_data = extract_msku_data(response.text)
variants = parse_variants(msku_data) if msku_data else []
return {
'title': title.text.strip() if title else None,
'variants': variants,
'variant_count': len(variants)
}
# Example usage
url = "https://www.ebay.com/itm/176212861437" # Product with size/color variants
data = scrape_ebay_product_with_variants(url)
print(f"Found {data['variant_count']} variants")
for variant in data['variants'][:3]: # Show first 3
print(variant)
This approach is significantly faster than using Selenium to click through every dropdown option. You get all variant data in a single request.
Scraping eBay Search Results
Search result pages are structured differently than product pages. Here's how to extract listings from search:
def scrape_ebay_search(keyword, pages=1):
base_url = "https://www.ebay.com/sch/i.html"
all_results = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
for page in range(1, pages + 1):
params = {
'_nkw': keyword,
'_pgn': page,
'_ipg': 60 # Items per page (max is 240, but 60 is safer)
}
response = requests.get(base_url, params=params, headers=headers)
soup = BeautifulSoup(response.content, 'lxml')
# eBay search uses <li> elements with class s-item
items = soup.select('.s-item')
for item in items:
# Skip the "Shop on eBay" header item
if 'Trending at' in item.text:
continue
product = {}
# Title and URL
title_elem = item.select_one('.s-item__title')
link_elem = item.select_one('.s-item__link')
product['title'] = title_elem.text.strip() if title_elem else None
product['url'] = link_elem.get('href') if link_elem else None
# Price
price_elem = item.select_one('.s-item__price')
product['price'] = price_elem.text.strip() if price_elem else None
# Shipping
shipping_elem = item.select_one('.s-item__shipping')
product['shipping'] = shipping_elem.text.strip() if shipping_elem else "Free shipping"
all_results.append(product)
time.sleep(3) # Be respectful between page requests
return all_results
Pagination tip: eBay uses _pgn for page number and _ipg for items per page.
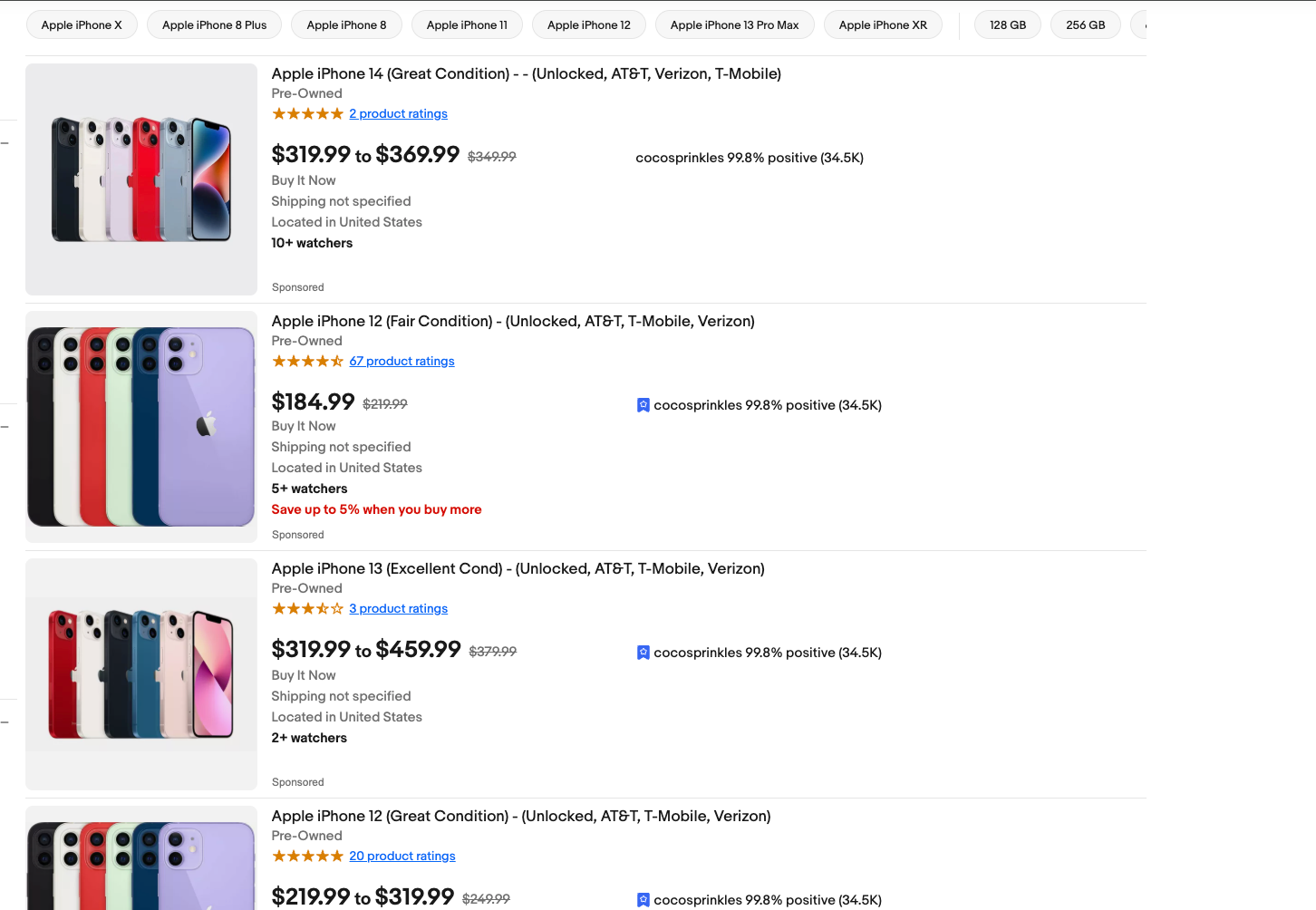
Setting _ipg to 60 or 120 reduces the number of requests you need to make, but don't max it out at 240—that's a red flag for bot detection.
Smart Rate Limiting: Going Beyond time.sleep()
Most tutorials tell you to add time.sleep(2) between requests. That works, but it's crude. Here's a smarter approach:
import time
from collections import deque
from datetime import datetime, timedelta
class RateLimiter:
def __init__(self, max_requests=60, time_window=60):
"""
max_requests: Maximum number of requests allowed
time_window: Time window in seconds
"""
self.max_requests = max_requests
self.time_window = time_window
self.requests = deque()
def wait_if_needed(self):
"""Wait if we're hitting the rate limit"""
now = datetime.now()
# Remove old requests outside the time window
while self.requests and self.requests[0] < now - timedelta(seconds=self.time_window):
self.requests.popleft()
# If we've hit the limit, wait until we can make another request
if len(self.requests) >= self.max_requests:
sleep_time = (self.requests[0] + timedelta(seconds=self.time_window) - now).total_seconds()
if sleep_time > 0:
print(f"Rate limit reached. Waiting {sleep_time:.1f} seconds...")
time.sleep(sleep_time + 0.1) # Add small buffer
self.requests.append(now)
# Usage
limiter = RateLimiter(max_requests=30, time_window=60) # 30 requests per minute
for url in product_urls:
limiter.wait_if_needed()
scrape_ebay_product(url)
This tracks your requests in a sliding window and automatically throttles when you approach the limit. It's particularly useful when scraping hundreds of pages.
Why this is better: Instead of blindly waiting 2 seconds between every request (which might be too fast or too slow), this adapts based on your actual request rate. You can burst quickly early on, then slow down as you approach the limit.
Handling eBay's Bot Detection
Even with proper headers and rate limiting, you might hit blocks. Here's what to do:
Rotating User Agents
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/115.0',
]
def get_random_headers():
return {
'User-Agent': random.choice(USER_AGENTS),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip, deflate',
'DNT': '1',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
Using Requests Sessions for Cookies
session = requests.Session()
session.headers.update(get_random_headers())
# Session maintains cookies across requests
response1 = session.get(url1)
response2 = session.get(url2) # Will use cookies from response1
Sessions help because eBay sets tracking cookies. Using the same session across requests makes your scraper look more like a real browsing session.
Exponential Backoff for Errors
def scrape_with_retry(url, max_retries=3):
for attempt in range(max_retries):
try:
response = session.get(url)
if response.status_code == 200:
return response
# 403 means we're blocked, 429 means rate limited
if response.status_code in [403, 429]:
wait_time = (2 ** attempt) * 5 # 5, 10, 20 seconds
print(f"Got {response.status_code}, waiting {wait_time}s...")
time.sleep(wait_time)
continue
except requests.RequestException as e:
print(f"Request failed: {e}")
time.sleep(2 ** attempt)
return None
Exporting Data to CSV
Once you've scraped your data, you'll want to store it. Here's a clean way to export to CSV:
import csv
from datetime import datetime
def save_to_csv(products, filename=None):
if not filename:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"ebay_products_{timestamp}.csv"
if not products:
print("No products to save")
return
# Get all unique keys from all products
keys = set()
for product in products:
keys.update(product.keys())
with open(filename, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=sorted(keys))
writer.writeheader()
writer.writerows(products)
print(f"Saved {len(products)} products to {filename}")
When Scraping Isn't the Answer
Before you build a scraper, consider these alternatives:
eBay's Developer API
eBay offers official APIs for accessing their data. The Finding API and Browse API can get you:
- Product search results
- Item details
- Category information
- Seller data
Pros: It's legal, stable, and won't get you blocked.
Cons: Requires approval, has rate limits (5,000 calls/day for basic tier), and doesn't include all data that's visible on the website.
If you're running a business that depends on eBay data, the API is worth the application hassle.
Pre-built Datasets
Services like Bright Data and Apify offer pre-scraped eBay datasets. You pay per record, but you skip the technical headache.
When this makes sense: If you need historical data or one-time analysis, buying a dataset is cheaper than building a scraper.
Legal and Ethical Considerations
Let's be real about the legal landscape:
- eBay's Terms of Service explicitly prohibit scraping. You're violating their ToS by doing this.
- Courts have generally ruled that scraping public data is legal (hiQ Labs v. LinkedIn, Meta v. Bright Data), but eBay could still ban your IP or take you to court.
- Don't scrape personal data. Seller names are one thing, but anything that falls under GDPR or CCPA protection is off-limits.
- Respect robots.txt. eBay's robots.txt mostly disallows scrapers except search engines. If you ignore it completely, you're on shakier legal ground.
My take: If you're scraping for personal research, competitor analysis, or building a small internal tool, you're in a legal gray area but probably fine. If you're scraping to build a competitor site or resell their data at scale, expect legal pushback.
Putting It All Together: A Complete Scraper
Here's a production-ready scraper that combines everything we've covered:
import requests
from bs4 import BeautifulSoup
import csv
import time
import json
import re
from datetime import datetime
class EbayScraper:
def __init__(self):
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
self.rate_limiter = RateLimiter(max_requests=30, time_window=60)
def scrape_product(self, url):
"""Scrape a single product page"""
self.rate_limiter.wait_if_needed()
response = self.session.get(url)
if response.status_code != 200:
return None
soup = BeautifulSoup(response.content, 'lxml')
# Extract basic data
product = {
'url': url,
'title': self._get_text(soup, 'h1.x-item-title__mainTitle'),
'price': self._get_text(soup, '.x-price-primary span'),
'condition': self._get_text(soup, '.x-item-condition-text span'),
'seller': self._get_text(soup, '.ux-seller-section__item--seller a'),
'scraped_at': datetime.now().isoformat()
}
# Try to extract MSKU data
msku_data = self._extract_msku(response.text)
if msku_data:
variants = self._parse_variants(msku_data)
product['variants'] = variants
product['has_variants'] = True
else:
product['has_variants'] = False
return product
def scrape_search(self, keyword, max_pages=3):
"""Scrape search results"""
base_url = "https://www.ebay.com/sch/i.html"
results = []
for page in range(1, max_pages + 1):
self.rate_limiter.wait_if_needed()
params = {
'_nkw': keyword,
'_pgn': page,
'_ipg': 60
}
response = self.session.get(base_url, params=params)
soup = BeautifulSoup(response.content, 'lxml')
items = soup.select('.s-item')
for item in items:
product = {
'title': self._get_text(item, '.s-item__title'),
'url': self._get_attr(item, '.s-item__link', 'href'),
'price': self._get_text(item, '.s-item__price'),
'shipping': self._get_text(item, '.s-item__shipping'),
}
if product['url']: # Skip header items
results.append(product)
print(f"Scraped page {page}, found {len(items)} items")
return results
def _get_text(self, soup, selector):
"""Helper to safely extract text"""
elem = soup.select_one(selector)
return elem.text.strip() if elem else None
def _get_attr(self, soup, selector, attr):
"""Helper to safely extract attributes"""
elem = soup.select_one(selector)
return elem.get(attr) if elem else None
def _extract_msku(self, html):
"""Extract MSKU data from page source"""
pattern = r'"MSKU":\s*(\{.+?\}),"QUANTITY"'
match = re.search(pattern, html, re.DOTALL)
if match:
try:
return json.loads(match.group(1))
except json.JSONDecodeError:
return None
return None
def _parse_variants(self, msku_data):
"""Parse MSKU into variant list"""
# Implementation from earlier
variations = msku_data.get('variationsMap', {})
combos = msku_data.get('variationCombinations', {})
variants = []
for combo_id in combos.values():
variant_data = variations.get(str(combo_id))
if variant_data:
price_data = variant_data.get('binModel', {}).get('price', {})
price_spans = price_data.get('textSpans', [])
variants.append({
'price': price_spans[0].get('text') if price_spans else None,
'in_stock': not variant_data.get('quantity', {}).get('outOfStock', False)
})
return variants
def save_results(self, results, filename):
"""Save scraped data to CSV"""
if not results:
print("No results to save")
return
with open(filename, 'w', newline='', encoding='utf-8') as f:
# Flatten variants for CSV
flat_results = []
for item in results:
if item.get('has_variants'):
item['variant_count'] = len(item.get('variants', []))
del item['variants'] # Too complex for CSV
flat_results.append(item)
if flat_results:
writer = csv.DictWriter(f, fieldnames=flat_results[0].keys())
writer.writeheader()
writer.writerows(flat_results)
print(f"Saved {len(results)} results to {filename}")
# Usage example
if __name__ == "__main__":
scraper = EbayScraper()
# Scrape search results
results = scraper.scrape_search("mechanical keyboard", max_pages=2)
scraper.save_results(results, "ebay_keyboards.csv")
# Scrape individual products
product_urls = [r['url'] for r in results[:5]] # First 5 products
for url in product_urls:
product = scraper.scrape_product(url)
if product:
print(f"Scraped: {product['title']}")
This scraper:
- Handles rate limiting automatically
- Extracts MSKU variant data when present
- Uses sessions for cookie management
- Exports clean CSVs
- Includes error handling (which I omitted for brevity, but you should add)
The latest Ebay Scraper Code 2026: https://github.com/carlsfert/web-scraper/tree/main/websites/ebay-scraper
Final Thoughts
Scraping eBay is technically feasible but comes with legal and ethical considerations. The techniques in this guide—MSKU extraction, smart rate limiting, and proper header management—will get you working code. But remember:
- Start small. Don't jump to scraping thousands of pages on day one.
- Respect rate limits. eBay's servers aren't your playground.
- Consider the API. For commercial use, eBay's official API is the safer bet.
- Don't be a jerk. If you get a cease and desist, comply with it.
The MSKU extraction technique is particularly valuable because it's not widely documented and gives you access to data that's hard to get otherwise. Use it wisely.
If you're building a serious business on eBay data, invest in proper infrastructure: rotating proxies, distributed scraping, and legal counsel. For personal projects and research, the code above will get you started without immediately tripping alarms.






![IPRoyal vs Oxylabs: Which provider is better? [2026]](https://cdn.roundproxies.com/blog-images/2026/02/iproyal-vs-oxylabs-1.png)

